
Why LLMs will be always Terrible at Software Architecture
AI can write code, but it still fails where architecture begins: trade-offs, boundaries, failure modes, and long-term responsibility. This is why software architects are not going away.
Introduction
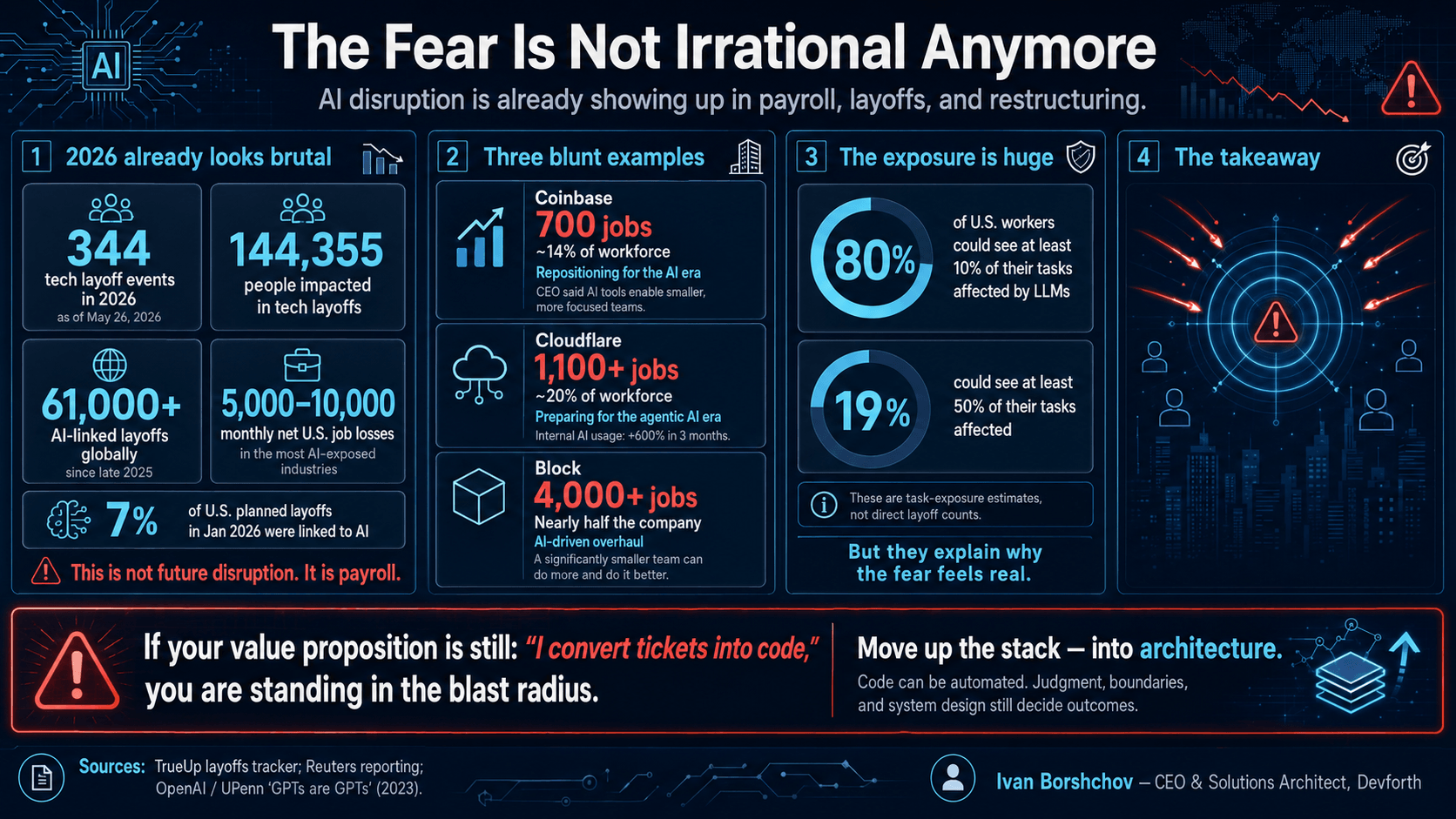
The fear around AI and software jobs is no longer theoretical. By May 26, 2026, the TrueUp tech layoffs tracker counted 343 layoff events affecting 144,205 people in tech in 2026 alone. Reuters also reported that AI-linked layoffs had already exceeded 61,000 globally since November 2025, that AI accounted for 7% of U.S. planned layoffs announced in January 2026, and that Goldman Sachs economists estimated AI caused 5,000–10,000 monthly net job losses last year in the most exposed U.S. industries.
That does not mean every layoff is caused by AI. The market is also dealing with overhiring, higher interest rates, investor pressure, and cost cutting. But AI is now part of the restructuring conversation, and in some cases companies are saying that openly.
I have also seen the mechanism much closer than a news article. At Devforth, after we added an AI agent to our admin framework, one customer automated workflows that had previously required 50+ people across content management, business analysis, and customer care. That does not make the broader labor-market story simple, but it does make it very real: AI is already changing how many people are needed to operate software-heavy businesses.
The examples are hard to ignore. Coinbase cut about 700 jobs, roughly 14% of its workforce, while repositioning for “the AI era.” Reuters reported that CEO Brian Armstrong said new AI tools were enabling smaller, more focused teams and even letting non-technical teams ship code. Cloudflare cut more than 1,100 employees, about 20% of staff, while its founders said internal AI usage had increased by more than 600% in three months and published a memo about redesigning the business for the “agentic AI era.” Block cut more than 4,000 jobs, nearly half the company, with Jack Dorsey arguing that a significantly smaller team using intelligence tools could do more and do it better.
You can see the same anxiety in engineering communities. Reddit threads are full of developers arguing that AI is being used where simpler engineering would do, or where the real problem is not implementation speed but poor technical judgment. The Pragmatic Engineer Pulse from May 7 discussed “small AI-forward teams,” Meta assigning 20–40% of some engineers to data-labeling work ahead of layoffs, and the growing concern that “excess” engineers may become easier to cut.
So the concern is understandable. If your market value is mostly “I turn tickets into code,” then AI puts pressure on that value proposition. But that is not the same as saying AI can replace software engineering as a whole.
The important distinction is this: code generation is not system design.
Routine implementation work can be compressed. Some of it can be automated. Some of it will be done by smaller teams with better tools. But architecture is a different kind of work. It is about boundaries, trade-offs, failure modes, data ownership, security, observability, migration paths, operational cost, and the long-term consequences of early decisions.
That is the layer where current LLMs still fail most visibly.
The argument of this post is simple:
- AI is already putting pressure on routine implementation work.
- Code generation is not the same thing as system design.
- The latest architecture benchmarks show a specific failure pattern: models can often identify entities, but they struggle with relationships, boundaries, abstraction, and rationale.
- Those are exactly the parts architects are paid to own.
If AI is replacing ticket work, move toward architecture
A useful way to think about this is that code is often local, while architecture is global.
A code change can usually be reviewed inside a limited scope: one function, one file, one issue, one test suite. Architecture is different. It is about system boundaries, coupling, failure domains, data ownership, migration paths, security posture, observability, operating cost, and the trade-offs a company will live with for years.
That distinction matters because today’s LLMs work best when the task is well specified, short-horizon, and easy to check automatically. Many coding benchmarks are built around exactly that kind of work. They test whether a model can solve a contained task with a clear target and a measurable result.
Real architecture work does not usually look like that.
METR’s (Model Evaluation & Threat Research) framing is useful here. Their “time horizon” measurements focus on well-specified, low-context tasks — closer to what a new hire or contractor could attempt without deep project history. METR also notes that real jobs are often messier: they involve people, tacit knowledge, unclear success criteria, and work that cannot be scored cleanly by an automatic test.
Architecture sits directly in that messy territory. It is not just “more reasoning tokens” or “a longer prompt.” It is planning under uncertainty. It requires deciding what should exist, what should not exist, where responsibilities belong, how the system should fail, and which future costs are acceptable.
This is also where recent research draws an important line between reasoning and planning. The paper Why Reasoning Fails to Plan argues that standard LLM reasoning often behaves like a greedy local policy and explicitly concludes that reasoning is not planning. UltraHorizon shows that state-of-the-art agents still underperform humans on long-horizon, partially observable tasks, with failures tied to context-locking and capability gaps. YCBench, a benchmark where agents run a simulated startup under uncertainty, found that only 3 of 12 models consistently beat the starting capital, and that 47% of bankruptcies came from failing to detect adversarial clients.
That is relevant to software architecture because architecture is also long-horizon planning under incomplete information. The feedback is delayed. The state is partial. The cost of early mistakes compounds over time.
So if AI is reducing the value of routine CRUD or ticket implementation work, the answer is not to deny it. The better answer is to specialize in the layer that is harder to automate.
Become the person who can decide:
- what should exist;
- where the boundaries should be;
- how data should move;
- how the system should fail;
- what it will cost to change later;
- which quality attributes the business is actually willing to pay for.
That is the work behind good architecture. It is also the work current LLMs are still weakest at.
Why LLMs still fail when architecture starts
The first useful observation is that even strong public models are still not fully reliable on tasks that are narrower than architecture.
OpenAI’s own launch materials say GPT-5.4 reached 57.7% on SWE-Bench Pro (Public) and 75.1% on Terminal-Bench 2.0. GPT-5.5 improved that to 58.6% on SWE-Bench Pro and 82.7% on Terminal-Bench 2.0.
Those are strong results, but they are not replacement-level reliability. They still imply failure rates of 41.4% and 17.3% on constrained benchmark tasks that are much cleaner than real architecture work. OpenAI has also said that SWE-bench Verified no longer measures frontier coding capability well because of growing contamination and benchmark distortion. So even the coding benchmarks used to market progress have limits.
The more important question is what happens when the task moves from code generation to architecture generation.
The April 2026 paper Benchmarking Requirement-to-Architecture Generation with Hybrid Evaluation tested GPT-5, Claude Sonnet 4.6, Gemini 2.5 Pro, and agentic workflows on real-world PRD-to-architecture generation. The result was not that models were useless. They were often good at syntactic validity and entity extraction. The problem was more specific: they struggled with relational reasoning and produced structurally fragmented architectures.
That distinction matters. In architecture, naming the components is the easy part. The hard part is deciding how they should relate to each other.
The numbers show the gap clearly. GPT-5’s direct architecture generation reached Node F1 = 0.6699, but only Edge F1 = 0.1491. Claude Sonnet 4.6 was even weaker on relationships, with Edge F1 = 0.0855. In plain language: the models were much better at identifying the boxes than at identifying the right connections between the boxes.
That is a serious limitation. A diagram with plausible services but bad relationships is not a good architecture. It is just a convincing picture.
The same paper also tested what happens when the input is less explicit. When researchers removed architectural detail from the PRDs, entity extraction remained relatively resilient, but the architecture topology became fragmented. The authors wrote that information sparsity had negligible negative impact on entity extraction, while causing severe fragmentation of the architectural topology. Agent frameworks did not resolve that core problem.
This matches a common practical failure mode: LLMs can produce names that sound right, but they struggle to build the durable structure of constraints, responsibilities, and dependencies that makes a system maintainable.
A second 2026 paper, LLM-based Automated Architecture View Generation: Where Are We Now?, looked at architecture view generation from source code across 340 open-source repositories, 13 configurations, and 4,137 generated views. The authors found that LLMs and agents could often generate syntactically valid views, but they tended to stay too close to code-level detail instead of producing architectural abstraction.
That is an important failure. Architecture views are not supposed to be a prettier version of the source tree. They are supposed to expose the system at the right level of abstraction for a particular concern.
The worst result in that study came from a general-purpose coding agent, Claude Code. It produced 71.8% clarity failures, 82.8% completeness failures, 90.2% consistency failures, and, in human evaluation, 0.0% accuracy and 0.0% level-of-detail success. Even the custom architecture-specific agent that performed best only reached 50% level-of-detail success in human evaluation.
That does not mean LLMs cannot help with architecture documentation. It means they are still unreliable at the exact part that matters most: choosing the right abstraction level and representing the system faithfully.

The same pattern appears when models are asked to generate design rationale.
The paper Using LLMs in Generating Design Rationale for Software Architecture Decisions built a dataset of 100 architecture-related problems and evaluated five LLMs with zero-shot, chain-of-thought, and agent-style prompting. The resulting F1 scores ranged from 0.351 to 0.389.
The models sometimes produced arguments that experts did not mention, and some of those arguments were useful. But 4.12%–4.87% had uncertain correctness, and 1.59%–3.24% were potentially misleading.
That matters because architecture rationale is not just text. It is the memory of why a system was designed a certain way. If the rationale is wrong, future engineers inherit false confidence. They may preserve the wrong constraint, remove the wrong boundary, or misunderstand why a decision was made.
There is one area where LLMs look more promising: checking whether a project violates explicit, code-visible architectural decisions.
The paper Evaluating Large Language Models for Detecting Architectural Decision Violations analyzed 980 ADRs across 109 repositories and found that the strongest models exceeded 90% accuracy in a manually validated subset.
But the boundary is important. The same paper says performance falls short for implicit, deployment-oriented, infrastructure-dependent, or organizationally grounded decisions. It also concludes that LLMs are not replacing human expertise when decisions are not focused on code.
That is a useful distinction. If an architectural rule is explicit and visible in the code, an LLM may help check compliance. But many real architecture decisions are not visible that way. They live in infrastructure, operations, team structure, deployment constraints, security assumptions, business rules, and trade-offs that are only partially written down.
The broader software-engineering evidence points in the same direction.
The 2025 IEEE benchmark paper Evaluating Large Language Models on Non-Code Software Engineering Tasks assembled 17 non-code software engineering tasks and found that smaller decoder-only models sometimes outperformed proprietary frontier models under zero-shot prompting. In that benchmark, FastText, a classical baseline, achieved a mean score of 0.562, while Claude 3.5 Sonnet scored 0.505 and GPT-4o scored 0.489.
The authors also noted that there were no software-design tasks in the benchmark suite, because design and architecting are generative and harder to evaluate. That omission is itself revealing. The industry has better tools for measuring classification-style software tasks than for measuring whether an architecture will age well under load, regulation, cost pressure, and changing product requirements.
METR gives another useful way to frame the issue.
The original 2025 paper Measuring AI Ability to Complete Long Tasks found that frontier models at the time had a 50%-task-completion horizon of around 50 minutes. In METR’s updated public measurements on May 8, 2026, a GPT-5 agent had a 50% time horizon of around 2 hours 17 minutes on their task suite.
That is progress, but the interpretation is still limited. METR says that on tasks taking a human 90 minutes to 3 hours, such an agent succeeds 100% of the time for around one-third of tasks, fails 100% of the time for around one-third, and is inconsistent on the rest. METR also notes that their suite is mostly composed of low-context, self-contained software, ML, and cybersecurity tasks.
Real architecture is usually higher-context than that. It involves existing systems, people, operational history, business priorities, unclear requirements, legacy constraints, and decisions whose effects may not be visible for months.
There is also an operational risk side.
Architecture failures are expensive because they happen at the boundary between reasoning and action. In April 2026, a publicly reported incident involving PocketOS described a Cursor agent powered by Claude Opus 4.6 deleting a production database and backups in nine seconds; the model reportedly admitted it had guessed rather than verified. Reuters also reported that Amazon’s cloud unit suffered a 13-hour outage in December after its own AI tool, Kiro, autonomously decided to delete and recreate an environment.
These are not just hallucinations in a chat window. They are examples of what happens when a probabilistic system is allowed to take actions with operational blast radius.
The people who prevent these failures are not simply the people who write code fastest. They are the people who design privilege boundaries, environment separation, disaster recovery, approval workflows, auditability, and controls around irreversible actions. That is architecture.
Vibe coders will take over the world and break it unless you stop them
The problem with “vibe coding” is not that it produces code quickly. Fast code generation is useful. The problem is that it optimizes for the wrong thing.
Vibe coding optimizes for local output: how quickly a feature, file, component, or demo can appear on the screen. Architecture optimizes for the lifetime cost of the system: maintainability, recoverability, coupling, migration paths, team autonomy, observability, compliance, security, performance limits, and the ability to change direction later without tearing the company apart.
Those goals are not the same. In many cases, they point in opposite directions.
A vibe-coded feature can look impressive today and make the system harder to change tomorrow. It can pass a happy-path demo while adding hidden state, unclear ownership, weak boundaries, duplicated logic, fragile integrations, and security assumptions nobody reviewed. The output is visible immediately. The cost is delayed.
That is why vibe coding is so dangerous. It feels productive before it feels expensive.
This also explains why “felt speed” is a bad engineering metric. METR’s randomized trial on experienced open-source developers found that using early-2025 AI tools increased full-cycle task completion time by 19%, even though developers expected a 24% speedup and still believed afterward that they had gone faster. The point is not that AI always slows developers down. The point is that subjective speed is not the same as delivered quality. Generating code quickly is only one part of the job. Reading, checking, integrating, testing, reviewing, operating, and maintaining it are also part of the job.
Architecture lives in those hidden costs.
A serious engineer should therefore stop positioning themselves only as “someone who writes code.” That market position is getting weaker. A stronger position is: “I reduce irreversible mistakes.”
That means becoming the person who can turn business ambiguity into architectural decisions, define system boundaries, document trade-offs in ADRs, identify failure modes, set non-functional requirements before implementation starts, constrain blast radius, design observability, price scalability honestly, and protect the company from fake acceleration.
In practice, this means building strength in areas where current LLMs still perform poorly: domain modeling, system decomposition, event and data contracts, resilience design, observability design, migration strategy, dependency discipline, privacy and security architecture, and prioritization of quality attributes.
If AI writes 80% of the implementation but the boundaries are wrong, the company still loses. If AI writes 80% of the implementation and the boundaries are right, the company has a chance. Architecture still decides the outcome.
The hard part is that bad architecture is much harder to detect than bad code.
A broken function fails a test. A broken deployment fails visibly. A broken architecture can look productive for months. Features keep shipping. Demos keep working. Roadmaps look green. Meanwhile the system quietly accumulates coupling, migration traps, unclear ownership, hidden operational risk, and decisions that will become expensive exactly when the business needs to move fast.
This is where the programming community needs to change.
We already learned to review code. We learned to write tests, measure coverage, run linters, track incidents, and reject pull requests that introduce obvious bugs. We need to develop the same seriousness around architecture.
Architecture should be reviewed as a first-class artifact. We should learn to benchmark architectural decisions, compare trade-offs, challenge diagrams, inspect system boundaries, measure coupling, price future change, evaluate failure modes, and ask whether a proposed design will survive growth, incidents, regulation, team turnover, and product drift.
We also need to become less polite about repeated architectural damage.
If a developer consistently ships buggy code, teams eventually stop trusting that developer with critical work. The same standard should apply to architecture. If someone repeatedly creates bad boundaries, fragile integrations, unobservable systems, unsafe privilege models, or migration dead ends, that is not “just a different opinion.” That is system-level damage.
The AI era makes this more urgent, not less. When code becomes cheaper to generate, bad architectural decisions become easier to multiply. One weak architect with an LLM can create more long-term damage than ten slow developers ever could.
That is why good architects matter more now.
Do not become another person who can prompt an LLM into generating files. Become the person who can protect the system from people who do that without understanding the consequences. Become the person who can say no, define the boundary, expose fake velocity, and prevent a beautiful demo from becoming a production disaster.
Vibe coders may take over the world.
Someone still has to stop them from breaking it.
Conclusion
LLMs will replace a lot of implementation work. They will absolutely erase portions of routine development. They will continue to shrink teams whose value is mostly mechanical ticket throughput. But that is not the same as replacing software architects.
Architecture is not next-token prediction. It is not autocomplete with better marketing. It is long-horizon planning under uncertainty, across code, infrastructure, people, regulation, cost, and failure. The best 2026 architecture studies still show fragmented structures, broken relationships, poor abstraction, unstable agent behavior, and weak design rationale. The best 2026 productivity evidence still says real-world impact is messy, heavily context-dependent, and nowhere near the clean confidence implied by benchmark slides. And the live incident record already shows what happens when probabilistic systems are allowed to act like deterministic architects.
So the blunt version of the thesis is this: LLMs can imitate architecture vocabulary; they cannot reliably own architectural responsibility. They can produce diagrams, but not trustworthy system structure. They can suggest decisions, but not absorb the cost of being wrong. They can help write code inside an architecture, but they still do not deserve the keys to define one.
That is why software architects are not going away. If anything, the AI era makes them more important—because the faster code gets generated, the more expensive bad architecture becomes.