GPT-J is a self-hosted open-source analog of GPT-3: how to run in Docker
Learn how to setup open-source GPT-J model on custom cheapest servers with GPU. Try to run the text generation AI model of the future and talk to it right now!
Generative Pre-trained Transformer is a generation of models used to produce human-like text based on some initial text (part of dialogs or some task).
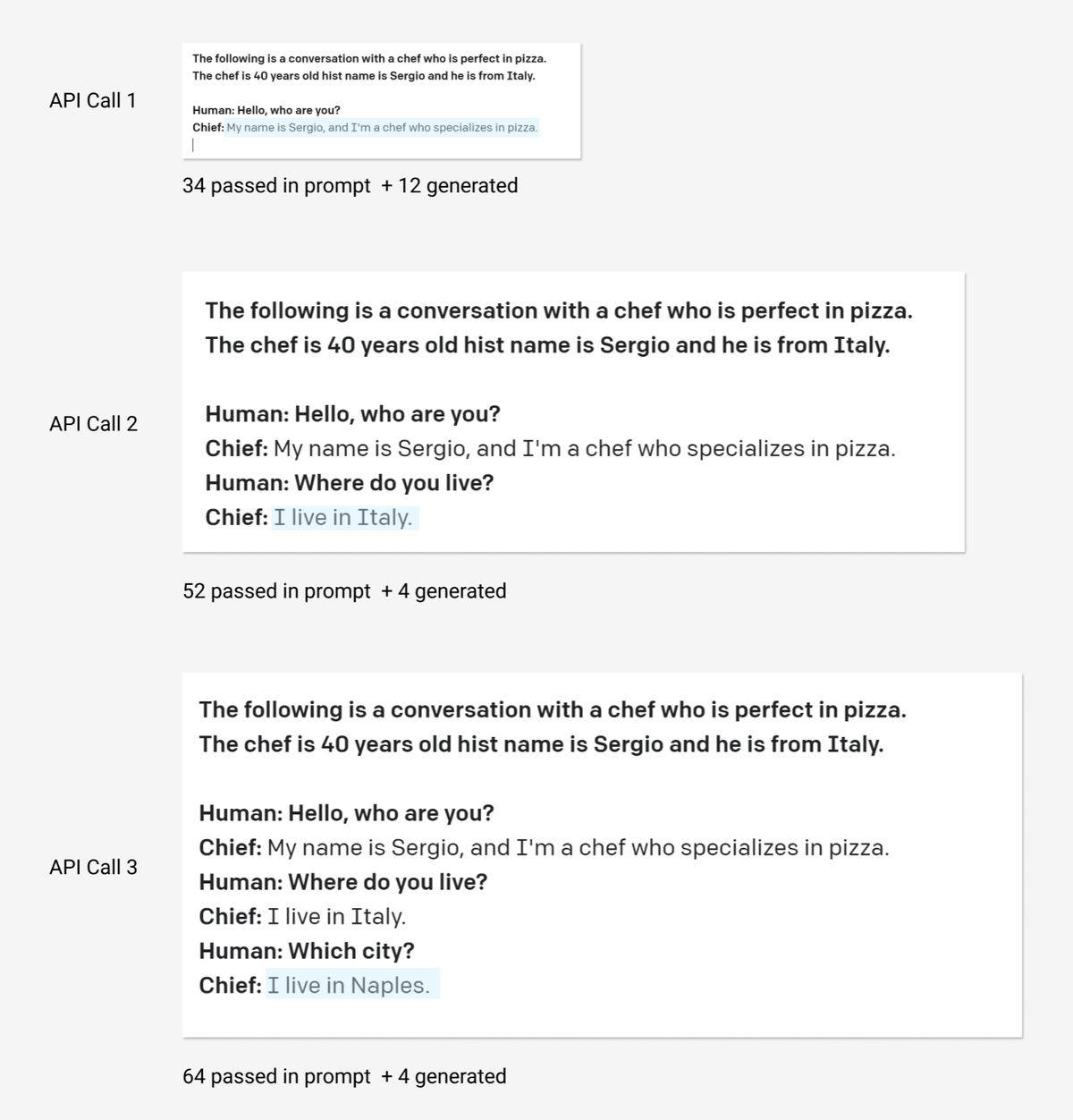
One of the most "hyped" models for this day is a GPT-3. When you see what GPT-3 generates you feel like "the future is here". You can run an example from the free OpenAI playground:

The text highlighted with blue was generated by GPT-3, everything else was typed by us. Is not it beautiful?
We feed a text (called prompt or context) into the model and it generates completion. Like in "resume sentence" exercises at school. So I specified that chief is from Italy and AI correctly picked up a town Naples, the city in Italy where pizza was borned.
GPT-3 model was trained by OpenAI company (Elon Mask is cofounder), and currently, you can only use it as paid REST API (which became available to anyone on Nov 18, 2021).

So even the small conversation mentioned in the example would take 552 words and cost us 0.004 on Curie.
Another team called EleutherAI released an open-source GPT-J model with 6 billion parameters on a Pile Dataset (825 GiB of text data which they collected).
EleutherAI was founded in July of 2020 and is positioned as a decentralized collective of volunteer researchers, engineers, and developers focused on AI alignment, scaling, and open-source AI research.
How powerful GPT-J is comparing to GPT-3?
There is a special dataset called LAMBADA which could be used to evaluate the capabilities of computational models for text understanding by means of a word prediction task.
| Model name | LAMBADA PPL (lower value is better) |
|---|---|
| GPT-2 1.5B | 10.63 |
| GPT-3 Ada | 9.95 |
| GPT-3 Babbage | 5.58 |
| GPT-J 6B | 3.99 |
| GPT-3 Curie | 4.00 |
| GPT-3 Davinci | 3.0 |
So GPT-J is better then Ada and Babbage, has almoast same power as Currie and a little bit less powerfull then Davinci.
Update from 2024
Recently we've launched an AdminForth framework for quick backoffice creation. It has a ChatGPT plugin and RichEditor which allows you to type text in your backoffice (e.g. text/html fields) very fast with using Chat-GPT/GPT-J.
Ways to run your own GPT-J model
Basically official GitHub GPT-J repository suggests running their model on special hardware called Tensor Processing Units (TPUs) provided by Google Cloud Platform.
Cheapest TPU is v2-8 (it has 8 cores of version 2), and such instance costs:
-
3,285 / month) - normal On-demand instances
-
986 / month) - cheaper preemptible instances (auto-rebooted every 24 hours, could stop at any time due to maintenance, might not always be available, not covered by SLA)
So price might seem not very comfortable for many projects or features in starting / experimental phase. Especially if your app has requests stream with higher capacity then one instance can handle, for example 100 characters are generated from 2000 input characters within 1 second (see charts at the end of post).
To reduce the final cost of hardware we can run the model on GPU which has 16 GB of video memory. For doing this there is open-source GPT-J container from Devforth published to Dockerhub GPT-J Image.
By the way, some slang in the names of use-cases:
-
Inference usage – means that we take model (it weights) and load them into GPU RAM, and then just use for producing output (generate text or classify things)
-
Fine-tuning the model – a completely different process in which we load a model into memory and then feed large bulk of new input data to adjust and re-train the model. A returned model then could be used for inference. This use-case requires much more resources
Which hardware could run the model**:**
-
To get hourly price in a lowest possible range 300 per month you can use: Vast.ai – a distributed computed marketplace where individuals rent out their GPU's and set their own prices. With couple of clicks I got an instance with 24 GB of VideoRAM for $0.33/hr.
-
You can find some cheap monthly options too, e.g. try GPU-K80 on vps-mart.com / gpu-mart.com which is 20 cheaper for anual payment. 24 GB VideoRAM, 20 Cores x64 CPUs 128 GB RAM, SSH with root access. Took 24 hours to get a server after payment. Drawback: No option to rent on per hour basis.
-
If you want to use larger cloud services with hourly payment and some guarantees of server availability and runtime (SLA), you can go with Scaleway Render S - was really easy to obtain, the instance is stable (a couple of clicks and you got the SSH and root), has 16 GB VideoRAM, 10 x64 CPUs, 45 GB RAM, costs a lot 810/month)
-
Someone might even say about AWS EC2, e.g. p3.2xlarge. Minimal spot prize costs 840/month), however, it is non-stable (could be terminated) spot instances, stable on-demand costs 3 times higher. We tried to get this instance from our old trusted AWS account but it required to increase AWS G Instances limit (with confused UI where you have to specify vCPU cores). It took a week and then required explaining why we need this instance and so on (Don't recommend if you are not ready to waste a lot of time)
The most interesting option is Vast.ai platform, also it allows you to play with the model with minimal expenses. So let us show you how to use it. Then we will also consider running model with plain SSH instance.
Setup GPT-J on Vast.ai
Vast.ai looks like fresh technological idea of new age. Comparing Vast.ai with regular hosting is like comparing Airbnb with hotels websites. It has no SLA guarantees (only actual host experience) but it is much cheaper and gives you a lot of options.
However there is a technical peculiarities: instead of direct SSH access to the server, you get SSH to the Docker container which will be spawned on user's machine. Luckily, you can specify which image to run, and proxy SSH port so actually it allows you to integrate several such instances smoothly even into a real-time application of any complexity. For this price, for profitable application you can keep 2-3 hosts running and load-balance requests between them, if one will go down others will serve requests.
So, let's spawn our Vast ai GPT-J instance. I will show how it works in step-by-step way. Go to https://vast.ai/console/create/ , then click "Edit Images & Config" button**,** scroll to "Enter the name of docker image", and type**:**
devforth/gpt-j-6b-gpu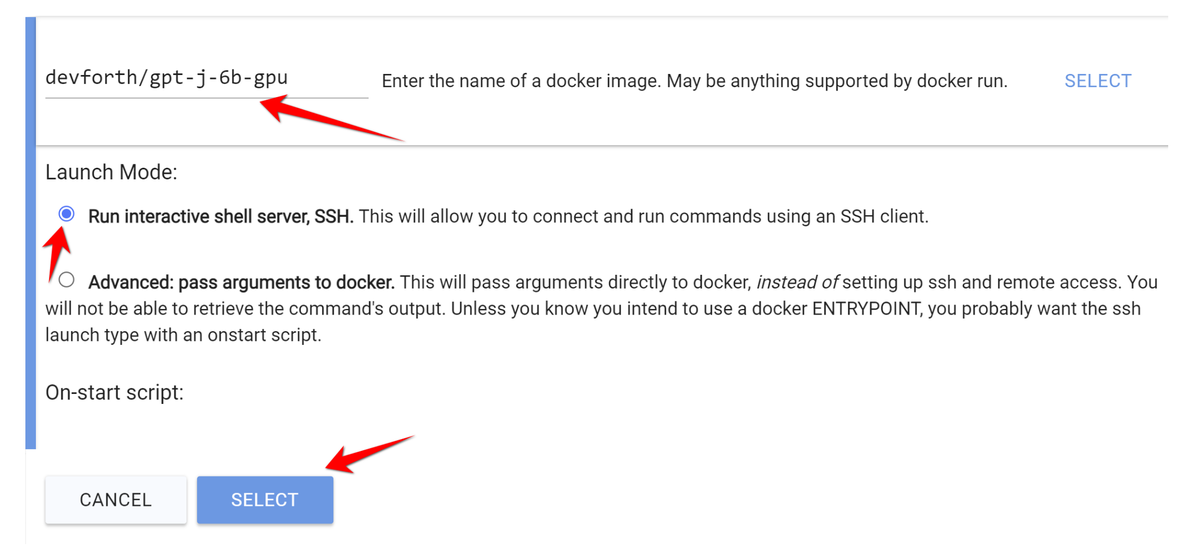
Running GPT-J Docker image on Vast.io
Use "SSH" option and click "SELECT".
Also, select filter by GPU memory:

Select the instance and run it. Then go to instances and wait while the image is getting downloaded and extracted (time depends on Download speed on rented PC):

Once the image is pulled**,** you will see CONNECT, instead of LOADING... on blue button. Press it and run the suggested command (first time you will also will need to pass public SSH key from your computer):
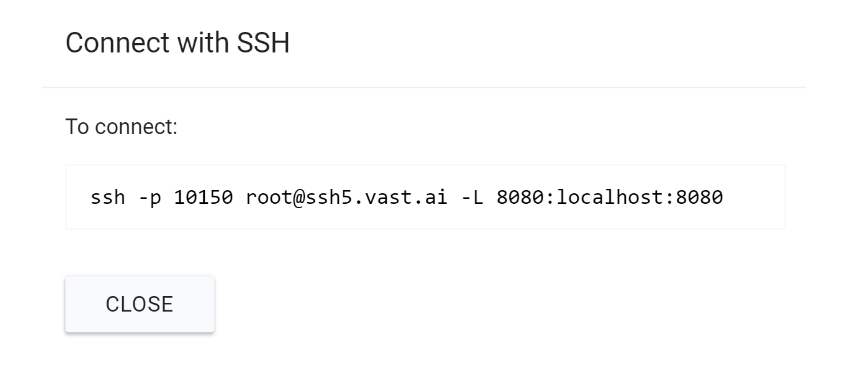
Connection to Vast.ai instance with 8080 port tunneling
In SSH shell run:
cd / && uvicorn web:app --port 8080 --host 0.0.0.0
Model loading takes several minutes, only then HTTP server starts listening on port 8080. Because of ssh port forwarding (-L flag in SSH command) we can run HTTP request to this port from our local PC and TCP connection will be safely forwarded to SSH:
Run GPT-J on Server with root access
First of all open README here and follow the "Prerequirements" section from gpt-j-6b-gpu-docker repository It contains the main steps needed to run GPT-J on a custom server:
-
Check NVIDIA Driver is installed and install it if needed
-
Install Docker with NVIDIA Container Toolkit
Once you are done with points above you are ready to run docker image:
docker run -p8080:8080 --gpus all --rm -it devforth/gpt-j-6b-gpu
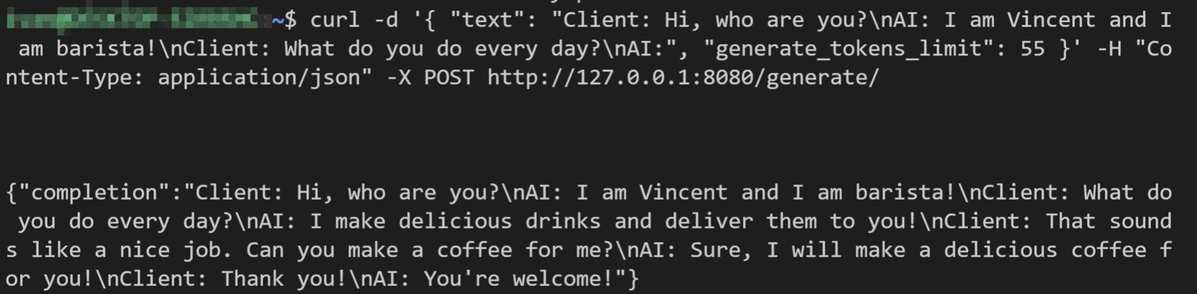
After that you should be able to make HTTP to public IP of your server, e.g. with Postman or curl or any HTTP request client. Example of call:
POST http://yourServerPublicIP:8080/generate/
Content-Type: application/json
Body:
{
"text": "Client: Hi, who are you?\nAI: I am Vincent and I am barista!\nClient: What do you do every day?\nAI:",
"generate_tokens_limit": 40,
"top_p": 0.7,
"top_k": 0,
"temperature":1.0
}
Speed of model and limitations
Already thinking about how you will use the model? Here are some facts.
The maximum length of text you can pass to context (prompt) plus generated text length per one call is 2049 tokens which is ~1.5k words or ~ 8-9k characters (both for GPT-J, GPT-3). If you need more you have to think about a way to resume context in next generation. Another approach for some tasks might be full-text presearch using classic methods e.g. typesense and then use result document as a knowledge.
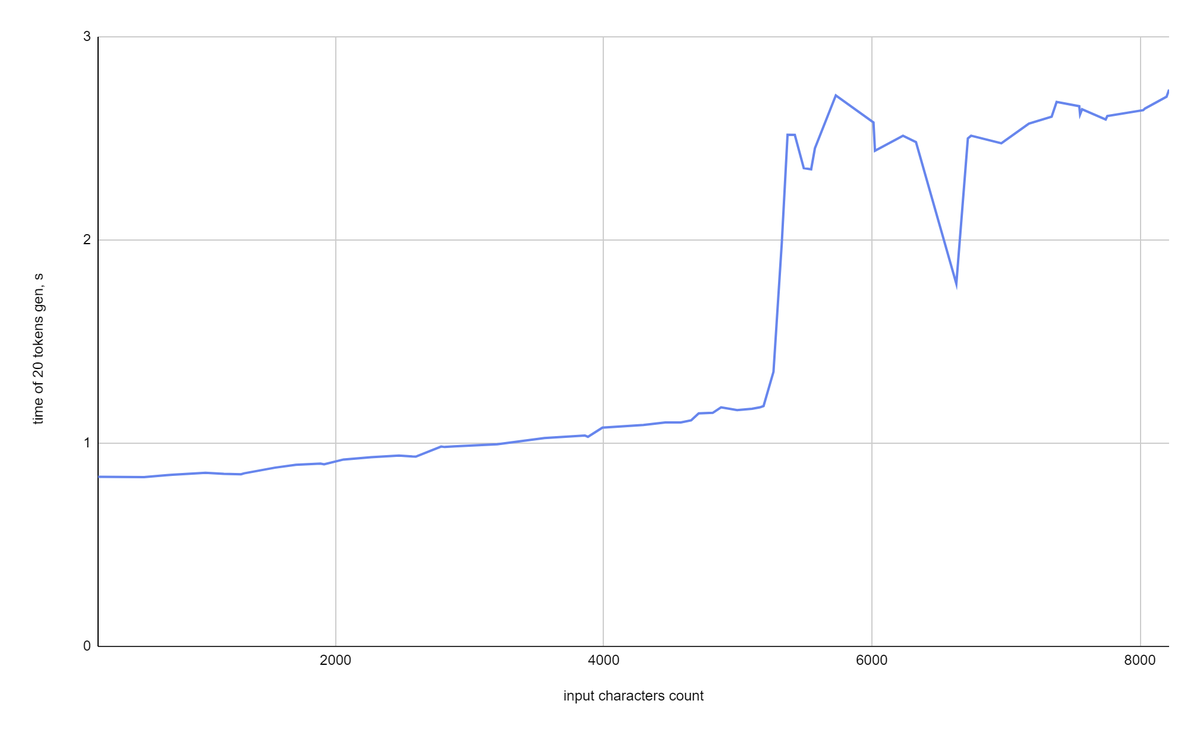
Let's check how quickly model produces text. On the first experiment we pass different amounts of text to the input but ask to generate fixed amount of tokens (generate_tokens_limit=20) using our GPT model test script:
-
So the time of one API response for inputs that are less then 5k characters (~6k tokens) is equal to 0.9 – 1.1 seconds.
-
For 5k – 8k characters it takes near 2.5 seconds to generate a response.
However once we froze the input context size for 43 tokens (227 Characters) and started to increase the number of generated tokens generate_tokens_limit=[100, 200, 300, ... 1500] we saw a significant increase in one API response time (up to 100 seconds):
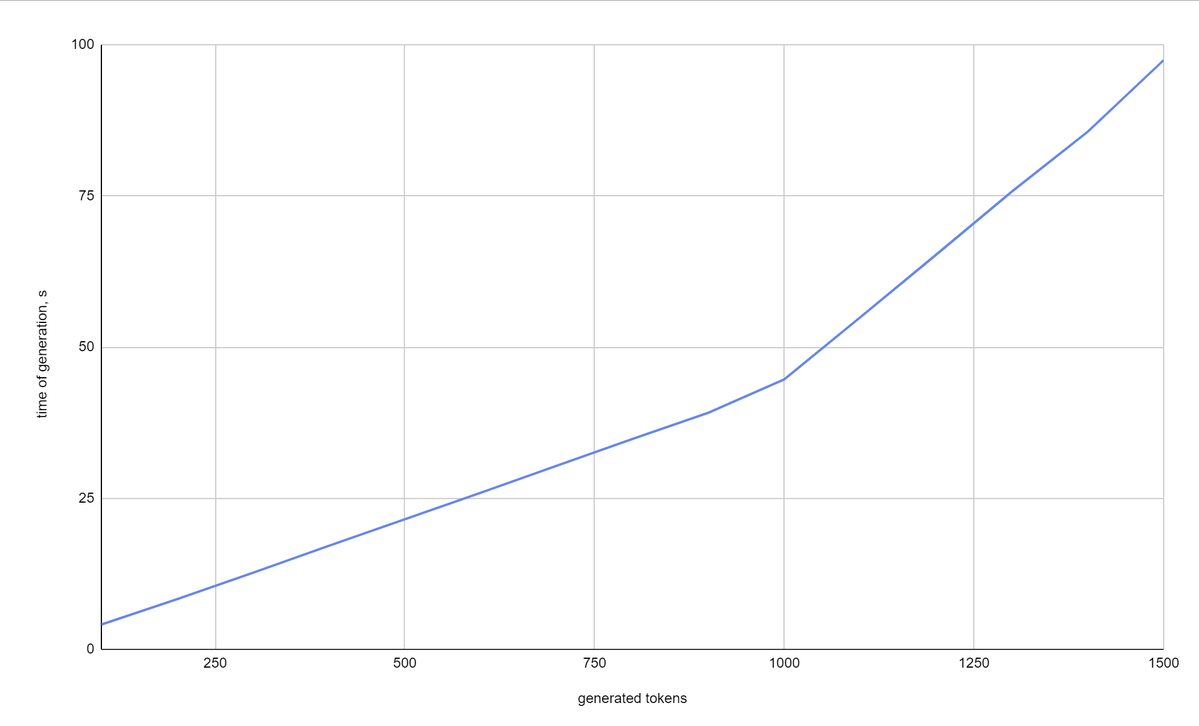
Important to note that each API call blocked on whole video card memory which means that you will not be able to run multiple requests in parallel, even if you use threads or multiple processes. If you need such concurrency, what you can do is spawn multiple instances and use a centralized web queue that will select the free instance. For vast.ai you can use asyncssh library for traffic forwarding. By the way, if you need to integrate this approach into your app, feel free to order Devforth services and we will do it professionally for you.
Thanks for reading. If you like the topic about GPT-J and want to read more posts about how we are using it in Tracklify, subscribe to our Twitter or Facebook.
Quick Links
-
How to measure tokens count for GPT-2/3/J your words programmatically: GPT2 tokenizer in transformers for python , Node.js GPT encoder
-
GitHub repo from Devforth with GPT-J image to run on GPU
-
Original GPT-J on Mesh Transformer JAX repo, could be used if you want to run it on Google TPUs